How to simplify your holiday festive meal planning
A Recipe-Diffficulty-Tagger and the MenuPlannerHelper App to the rescue!
By h-rm on 22 Dec 2017
Once again, the holiday season is upon us. As you go about your celebrations, you may be both excited and overwhelmed by all the various gatherings and parties. Some of us will attend as guests, and perhaps a few of us might be hosting. Should you find yourself preparing the whole meal or offering to contribute a dish or two and in the mood for homemade culinary adventures, there’s a little web application, called the MenuPlannerHelper (abbreviated as MenuHelper) I developed a while back that could come in handy.
The inspiration for its creation come from the fact that while I generally browse for new recipes to try, I sometimes find myself in situations where there will be recipes with accompanying food photography that look amazing and seemingly ‘doable’, yet upon embarking on the preparations, they present as more challenging than originally anticipated. In those scenarios, I find myself wishing that there might be an opportunity to use the ingredients for another similar but ‘simpler’ recipe. Likewise, there are other occasions, when a recipe turns out somewhat less complicated and you might wish to add some sophistication without over-tweaking it. Having cooked with others and listened to various kitchen nightmares, I have reason to believe that my experiences are not unique.
When festivities and inherent traditions place us under time, logistical and resource constraints, you don’t necessarily have much room to “mess up” when you are preparing a meal for others. With various things to coordinate, the last thing we really need while multi-tasking is a kitchen disaster!
This is where the MenuHelper app can be useful.
It was developed to help categorize recipes into different levels of complexity so that one could experience less stress and more enjoyment in coordinating the preparation of various dishes for e.g. a dinner party. Importantly, because of how it is trained to categorize recipes for relative preparation difficulty, one could further associate recipes based on the degree of similarity between their ingredients. This becomes handy if you wish to pivot between difficulty levels but also use similar ingredients that you may already have available.
But how does one actually classify recipes?
Not all recipes are created equal – I learnt this the hard way. Recipes differ on the number of ingredients whether they are exotic or locally sourced, how ingredients are prepared, the type of cooking technique or the equipment required, and so forth. If there would be a way to classify recipes as ‘easy’ or ‘challenging’ perhaps this information could help one to better plan and prepare the combination of dishes for a festive meal.

Interestingly, as I sifted through various sources of recipes the information about its preparation difficulty is not always available, nor is it often explicitly stated. It is possible that how difficult a recipe is may depend on your cooking experience, and it might be best left to self-discovery. Yet basic and advanced cooking classes exist, so it might be worth asking:
Could we learn from available recipes that are already categorized for their relative difficulty, which aspects or features contribute to their preparation ease or complexity?
The ingredients and steps involved:

Details of i) building a Recipe-Difficulty-Tagger and ii) developing the MenuPlannerHelper App
– DATA
Relative to many online recipes, BBC Good Food has a decent collection of recipes with information on the difficulty of a recipe.
I coded a web-recipe scrapper to automatically scrap all available (~10,000 at the time of scraping) recipes from BBCgoodfood.com. This included information on Ingredients, Instructions, as well as additional recipe information e.g. difficulty, preparation time, etc.
– PRE-PROCESSING
Like numerical data, text data also requires some form of “pre-processing”, which aims to clean up information that is not task-relevant and/or to restructure the data for subsequent analyses. To this end, I employed techniques from Natural Language Processing (NLP), which can be appreciated as the union of Artificial Intelligence (AI) and linguistics. NLP involves developing and using algorithmic and/or probablistic analysis of written language to automatically derive some insights from text data.
In particular, I borrowed the Conditional-Random-Field Ingredient Phrase Tagger developed by the New York Times (NYT) with optimization and inference using the CRF++ implementation to help with predicting the sequence of ingredient information. I modified the NYT Ingredient Phrase Tagger specifically to help remove quantity and units’ information from each BBCgooodfood recipe’s ingredient phrases and also to retrieve the name(s) of ingredients used.
Among various tweaks to the publicly available NYT ingredient phrase tagger code given the different data structure between NYT Cooking vs BBC Good Food recipes, as well as what might be deemed as collective unit terms e.g. ‘clove’, ‘bushel’, ‘pinch’, I also modified the NYT Ingredient Phrase Tagger utility code to account for metric units, since the recipes from BBC Good Food are written in British rather than American English.
Subsequently, the recipe ingredient and instruction text data were tokenized, i.e. they went through an algorithmic process that breaks down strings of words into its linguistic components e.g. words vs. non-words, parts-of-speech etc. so you could choose to keep only those elements of interest.
– TOPIC-MODELING
Next, I performed topic-modeling — an un-supervised machine learning approach that discovers the associations between words, topics, and documents using Latent Dirichlet Allocation (LDA)LDA.
The LDA topic-model assumes that a specific probabilistic model generates all the documents. Inherent in this assumption is that all documents share the same set of topics, but each document exhibits a mixture of topics (drawn from a DirichletDir prior Dir_a), with some being more salient than others. The words associated with each topic is related to a multinomial distribution over the range of vocabulary (drawn from a Dirichlet prior Dir_b).
LDA assumption: generated documents consist of distributions of topics, which are distributions of words.
This means that for any given observed collection of documents, we are trying to infer the latent variables i) the probability of words being used for each topic –– a word-topic association, and ii) the probability of each topic appearing in each document –– a topic—document association based on observed variables; the vocabulary itself. The inference process is typically derived through Gibbs sampling, or formulated as an optimization problem using variational inference, and tuning the two hyper-parameters a) and b) which regulate the prior distributions.
While other topic-models would likely also yield sensible topic clusters; LDA was opted because its learned topics are generally more concise and coherent, and it is considered a strong choice for applications in which a human end-user is envisioned to interact with the learned topics.
I implemented LDA separately on tokenized ingredient and instruction text data across all recipes using Python’s scikit-learn (although you can also do so with the Gensim library). After some iterative process in assessing the number of latent topicsNtopics from the collection of recipes, the final LDA model yielded generally meaningful ingredient (N=100) and instruction (N=80) topics.


– CLASSIFICATION
With the LDA ingredient and instructions topics derived, I assessed a few Classification Models that included the probabilistic topic-word association matrices as input features to predict recipe difficulty (‘easy’ vs. ‘more challenging’). The general model takes the form (also shown in FIG2.):
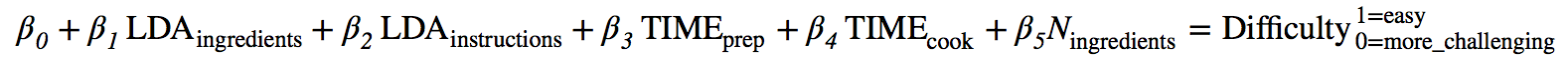
Ensemble (Gradient-boosted & Random Forest) classification Trees and Logistic Regression Models with different regularization e.g. Lasso(L1) & Ridge(L2) parameters were compared.
– TESTING-VALIDATING
To address the uneven proportionsample-issue of recipes for each difficulty category, the number of easy recipes was downsampled to match those of the ‘more-challenging’ recipes.
To assess the different models, 20% of sample data was held for final testing, and the remaining 80% was further split into 70% for model training and 30% for model development-testing.
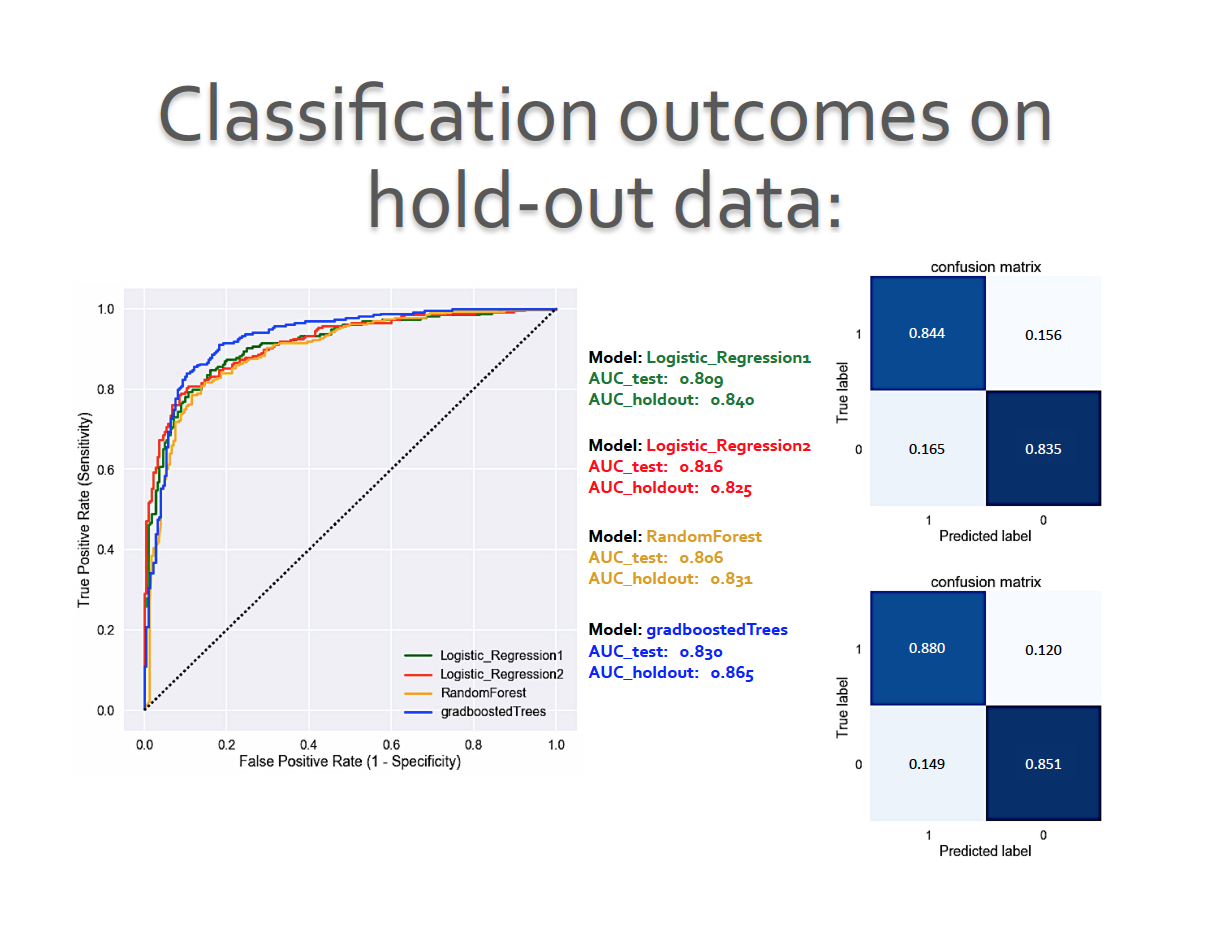
The outcome metrics of interest here were area under the curve, as well as precision (% of selected items that are relevant) and recall (% of relevant items selected, also commonly known as ‘sensitivity’):

The different models do comparably well after tuning for their respective parameters (e.g. learning rate, number of trees, training features etc.) with K-fold cross-validation. The 2 best performing models: Logistic_Regression1_lasso and gradboostedTrees yielded comparable recall and precision metrics ~84—86%, as seen in the confusion matrices below.
FEATUREs contributing to recipe difficulty
With our classification models yielding reasonable precision and recall metrics, we could start to probe into features contributing to a recipe’s preparation ease or complexity:
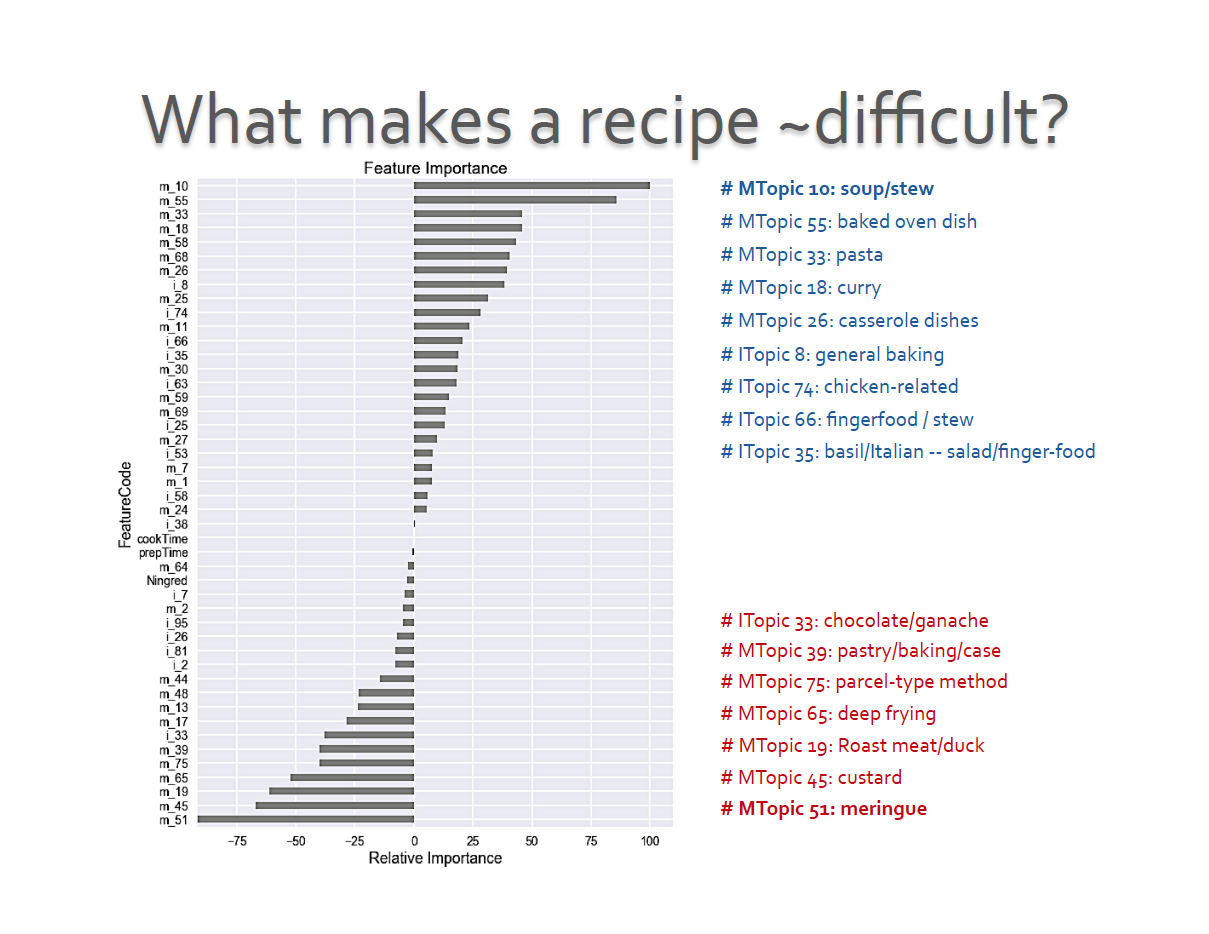
In addition to providing a probability of the associated topics, the LogisticRegression model with lasso regularization provides us some helpful insights into understanding what might be relevant features contributing to making a recipe easy or more challenging:
– EASY Recipes: those with instructions or cooking methods that involve making soups or stews and one-pot dishes (baked or otherwise) as well as ingredients that incorporate general baking, chicken, Italian herbs, or related to finger-food
– More-Challenging Recipes: those that have ingredients related to using chocolate and instructions or methods that involve e.g. making ganache, pastry, parcels; deep-frying, roasting; or preparing custard and especially meringues
APPLICATIONs
Now that we have a working recipe-difficulty-tagger (classification model), we could start tagging (existing and new) recipes within the collection that doesn’t yet have a difficulty category.
Apart from classifying recipes for their difficulty, I was also interested in providing alternative suggestions that could still make use of ingredients similar to those listed in the original recipe. To this end, I further employed the K-nearest-neighbors (KNN) algorithm on the LDA document-topic association matrix derived for ingredient topics across all recipes. Doing so, we could find K other recipes (documents) whose distribution of ingredient-topics are closest to any recipe of choice (as measured by cosine-similarity).
Below is an early version demo of the MenuPlannerHelper App!
Happily, the Recipe-Difficulty-Tagger and MenuPlannerHelper App serve as decent working proof-of-concepts and can indeed be used with the current recipe collection from BBCgoodfood.com.
Some thoughts on how to further improve and extend the work here…
APPLICATION EXTENSIONS:
– One could apply the recipe-difficulty-tagger to other (online and/or analog) recipe collection.
– We could also assess if similar ingredient and instruction topic features overlap across different recipe collections for difficulty. There may be a ‘universal’ set of features that could be approximated (and updated) to tag recipes for difficulty.
– Since the concept of ‘difficulty’ may be subjective, one could potentially personalize the MenuHelper app to track your culinary adventures over time. This in turn might mean that personal perspectives on what is subjectively easy or challenging could fine-tune the recipe-difficulty-tagger model to fit your level of comfort and may be used to suggest more challenging alternatives should you feel up for it.
ROOM for IMPROVEMENTs in data and modeling pipelines:
– The issue of unbalanced class proportionsample-issue and modeling could be further assessed with stratified k-fold cross-validation on the training data, adapting the data resampling with bootstrap aggregating (‘bagging’), or indeed adjusting the class-weights.
– Using a more objective way to select the number of topics in the topic-modelingNtopics , as well as other ways of defining relevant recipe features from recipe instructions e.g. context of words maybe useful and word2vec may help with finding these.
I look forward to trying out some of these ideas and sharing updates on another occasion.
Meanwhile, if you find yourself using recipes from BBCgoodfood why not give the MenuHelper App a go! You never know, there could be an easier or similarly delectable recipe that could help simplify your holiday festive meal preparation.
Until next time, Happy Holidays to all!
Postcript:
The use of recipes as a motivating dataset for exploring topic-modeling and application development may seem frivolous. However, the methods, learning algorithms, and ideas integrated in the work described here have applications that can be extrapolated to other domains and problems that deal with unstructured text information or others requiring feature engineering.
FOOTNOTES:
LDA: An unfortunate sharing of acronym: Latent Dirichlet Allocation (LDA) is distinct from Linear Discriminant Analysis (LDA), an algorithm that seeks to find a linear combination of features characterizing or separating two or more classes of objects or events.
Dir: The “Dirichlet” distribution describes a distribution of distributions.
Ntopics: A more objective way to determine the ‘optimal’ number of topics for a corpus of documents is through cross-validating a model’s perplexity – the measure of how well a probability model predicts a data sample. An overview of applying this heuristic using the ldatuning R package is given here, and a tutorial using the Text Mining and Topic Modeling Toolkit for Python can be found here
sample-issue: Some heuristics: on how to deal with imbalanced data and on the ‘right’ way to oversample for predictive modeling.
Link: GITHUB_repo
TAGs: NLP, classification, recipes